Jason W. Gullifer, Ph.D.
Computer Science Teacher
Marianopolis College
Language Entropy
Quantifying multilingual experience with language entropy
I developed a methodological approach using entropy (a measure of uncertainty and diversity; Shannon, 1948). Language entropy estimates individual- and contextual-level differences in the extent to which multiple languages are engaged (Gullifer et al., 2018, 2021; Gullifer & Titone, 2020, 2021). I developed and tested an open-source R package to compute it from questionnaire data.
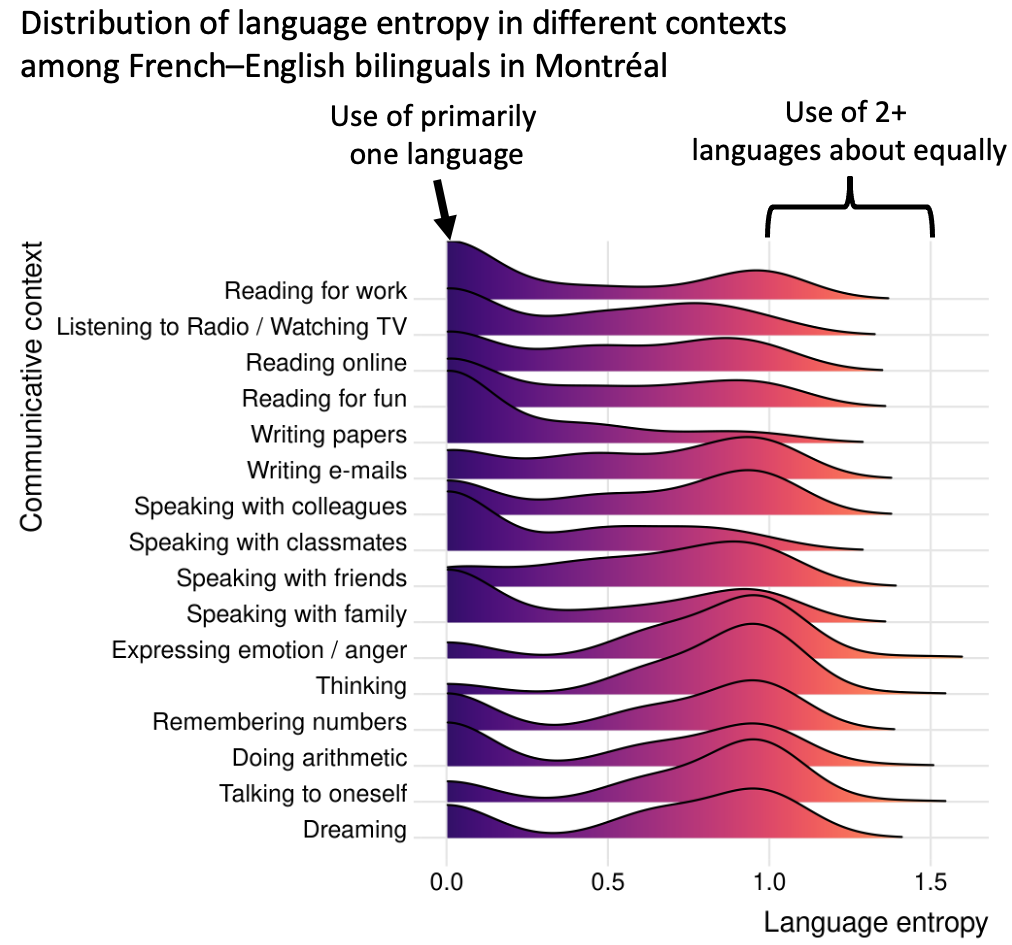
When two or more languages are engaged equally often, language entropy is high. When one language dominates, language entropy is low. Language entropy indexes the degree of language-related uncertainty for an individual or environment: in high entropy situations when multiple languages are equally likely, uncertainty is also high (Gullifer & Titone, 2021). The measure can be computed from self-report or objective data about language usage in different contexts (e.g., language use in the home vs. language use at work).

Below you can see the distribution of language entropy for a sample of bilinguals living in Montreal in different communicative contexts. You will see that some contexts, lhavereading and writing for work purposes, have low language entropy on average, meaning that people tend to prefer using one language. Other contexts, like thinking and dreaming, have high language entropy, meaning that people tend to prefer using two or more languages.
In my research on bilingual adaptation, I have found that individual differences in language entropy relate to aspects of language proficiency, executive control, and brain organization. In other words, bilingualism adapts the neurocognitive systems responsible for language and control.
There are many different ways to measure language diversity among bilinguals and multilinguals. Check out my work on network science to see more!