Jason W. Gullifer, Ph.D.
Computer Science Teacher
Marianopolis College
Network Science
Using network science to model the social engagement of language
Many aspects of cognition and language can be modeled as networks: areas in the brain, words in the mental lexicon, interactions between individuals in the environment, and so on. While network models of multilingual language use have been constructed from sources of online usage, like Twitter (e.g., Eleta & Golbeck, 2014), they have not been widely constructed from in-person usage.
In recent work with the Social Network Team in the Titone lab, we used networks to model data about individuals’ language engagement for various topics of conversation (e.g., politics, sports, moral issues, religious issues) as a way to compare languages and contexts of usage (e.g., formal vs. informal settings; Tiv, Gullifer, et al., 2020). The topic networks are illustrated below.
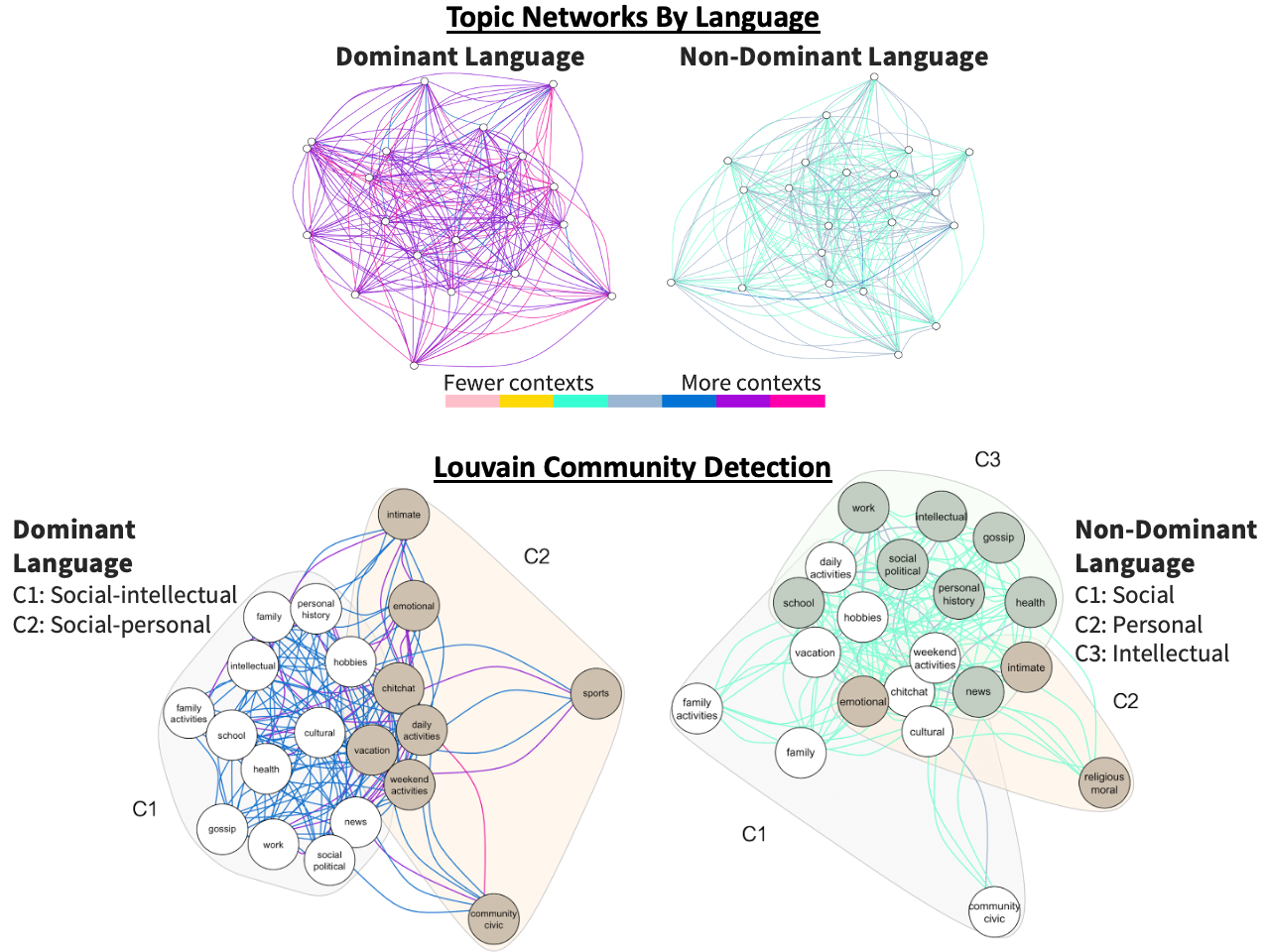
To create these networks, administered a survey that asked participants the languages that they used to discuss different topics of conversation in different communicative contexts. We treated topics as nodes in a network and connected them via edges if they were discussed in the same language. We then weighted the edges by the number of contexts in which they occurred. Analyses showed that dominant language networks were larger (more topic nodes) and more integrated (higher density, higher edge strength) compared to the non-dominant language. In other words, people reported talking about more topics across a broader array of contexts in their dominant vs. non-dominant language. Crucially, community detection (via the Louvain algorithm) revealed more communities of topics (i.e., densely connected groups) in the non-dominant language. This suggests that bilinguals in Montreal leverage their non-dominant language for more specialized purposes, potentially as a means of controlling language-related uncertainty.
You can also check out the project on OSF.